全国服务咨询热线:
17351412161
17351412161
——解读 ACS Synthetic Biology 2025 新研究
Cell-Free Protein Synthesis as a Method to Rapidly Screen Machine Learning-Generated Protease VariantsThornton et al., ACS Synth. Biol., 2025
一、为什么“机器学习设计蛋白",仍然离不开实验?
近年来,机器学习(Machine Learning, ML)在蛋白科学领域的影响力迅速扩大。从 AlphaFold 带来的结构预测革命,到各类序列生成模型用于蛋白设计,算法正在以未有的速度探索蛋白序列空间。
然而,一个现实问题始终存在:算法只能“提出假设",而蛋白功能的优劣,仍然必须由实验数据来验证。
尤其是在酶工程和功能蛋白优化中,ML 模型对训练数据提出了更高要求——不仅要多,还要真实反映蛋白功能差异。传统依赖细胞表达、纯化和动力学表征的流程,往往周期长、通量有限,很容易成为 ML 迭代的瓶颈。
在这一背景下,Thornton 等人在 ACS Synthetic Biology 发表的这项研究,给出了一个具代表性的解决思路:
👉 将无细胞蛋白合成(CFPS)直接嵌入机器学习驱动的蛋白设计流程中。

二、研究思路一览:一个典型的“Create–Test–Learn"闭环
这项研究围绕一种人工设计的蛋白酶 Con1 展开,目标是提升其催化活性。整体流程可以概括为三个阶段:
Create(设计)
基于结构预测和计算分析,筛选出可能影响底物结合的关键残基区域,并进行多位点突变设计;
Test(测试)
利用无细胞蛋白合成体系,在体外快速合成蛋白变体,并直接进行酶活性检测;
Learn(学习)
将“序列—功能"数据输入主动学习算法(ALDE),由模型推荐下一轮更有潜力的突变组合。
通过仅两轮筛选、约百个变体,研究者成功获得了酶活性提升约 4 倍的突变体,展示了该流程在效率上的显著优势。
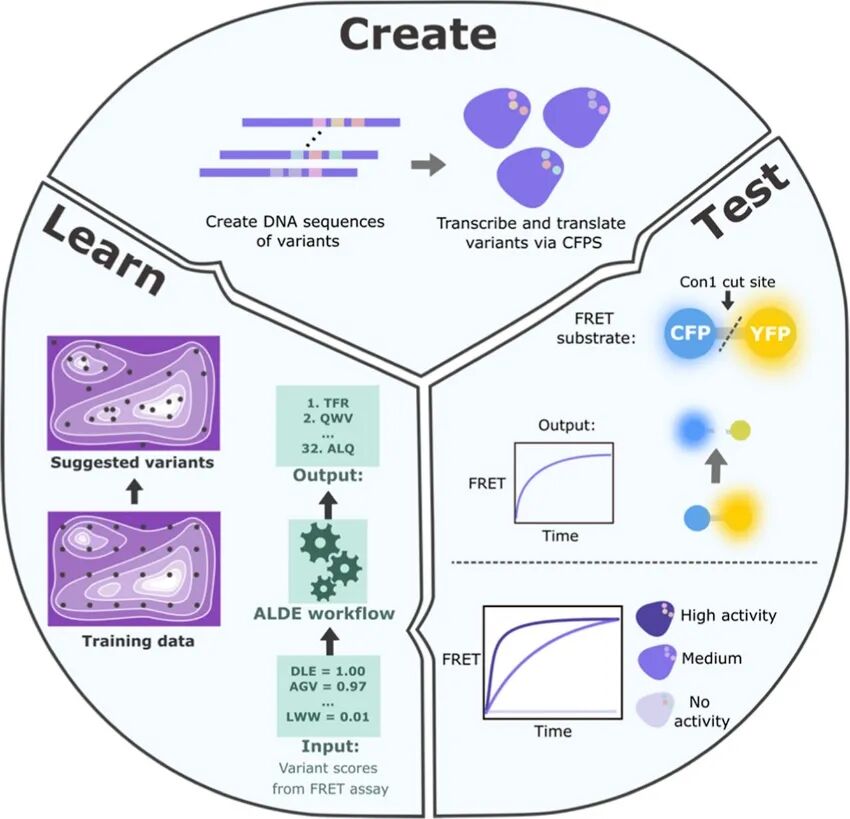
Create–Test–Learn 工作流程示意图(Thornton et al., ACS Synth. Biol., 2025)
三、无细胞蛋白合成在这里“厉害"在哪里?
值得注意的是,作者并没有把 CFPS 当作“传统细胞表达的替代方案",而是将其定位为机器学习实验数据的加速器。
从方法学角度来看,CFPS 在这一工作中体现出三点关键价值:
快速获得“可比较"的功能数据
研究中并未追求严格的动力学绝-对参数,而是通过统一条件下的反应初始速率作为 fitness 指标。事实证明,这种相对比较数据已经足以支撑 ML 对突变体优劣的判断。
开放体系,实验设计更自由
无细胞体系不受细胞生存、毒性或底物通透性限制,尤其适合早期功能筛选和多突变组合的测试。
实验速度,决定 ML 是否真正“跑得动"
当一轮蛋白表达和功能测试可以在数小时内完成,机器学习的“主动学习"优势才能被真正释放。
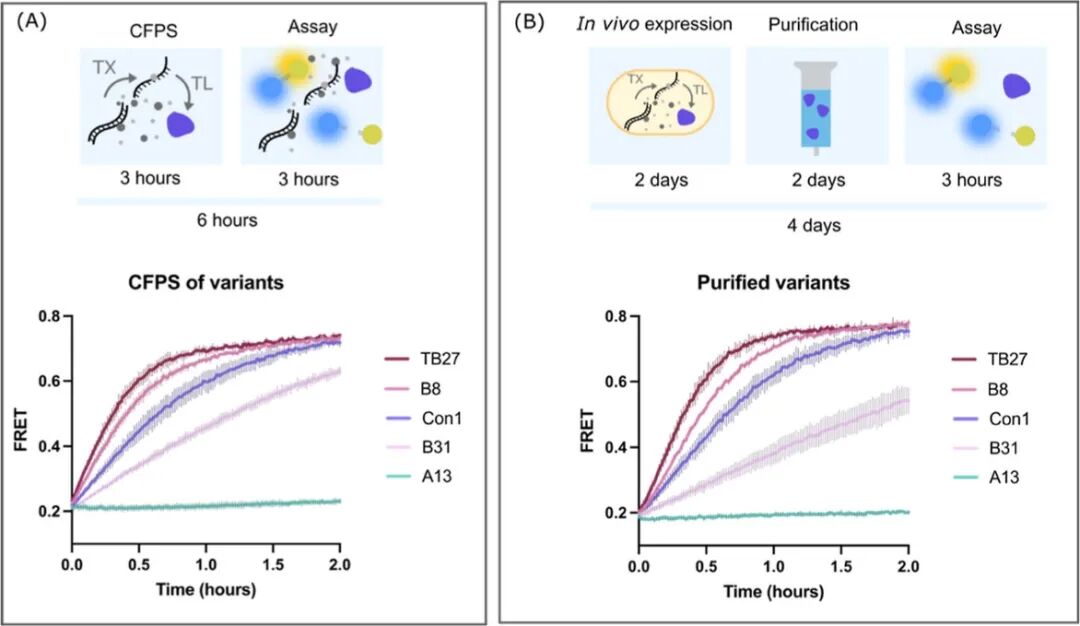
CFPS 与纯化蛋白活性对比(Thornton et al., ACS Synth. Biol., 2025)
四、从文献到产业实践:稳定 CFPS 平台的重要性
文中作者也明确指出,如果采用更成熟、标准化的无细胞蛋白合成体系,该流程在通量、重复性和自动化方面仍有提升空间。
这恰恰反映了当前行业的一个重要趋势:无细胞蛋白合成正在从“实验室方法",演进为“工程化工具"。
在这一方向上,珀罗汀生物(PLD Technology)正致力于将无细胞蛋白表达打造成可直接嵌入蛋白设计、筛选和验证流程的通用工具,服务于酶工程、功能蛋白研究以及 AI 蛋白设计等场景。
当 CFPS 不再需要研究者投入大量精力进行体系搭建,而是能够稳定输出高质量蛋白和功能数据时,机器学习模型的优势才能被充分放大。
珀罗汀生物联合自动化仪器进行高通量筛选应用
五、总结:蛋白工程的核心竞争力正在发生变化
这项研究传递出一个非常清晰的信号:
未来蛋白工程的竞争,不仅是算法的竞争,也不仅是实验技术的竞争,而是“数据生成效率 × 设计迭代速度"的综合竞争。
无细胞蛋白合成,正在成为连接“计算设计"与“实验验证"的关键桥梁。而当这一桥梁足够稳定、足够快速,蛋白工程的创新节奏也将被重新定义。
微信扫一扫
